Kernel Locking —Deep Dive into Spinlocks — Part 1
The Linux Kernel provides a variety of locking primitives. Each one of them behaves in a unique way that makes it more or less suitable to a specific use case. Some locking primitives are suitable for when a task can sleep, others can be used in cases where you don’t want to block readers of your critical code section and so on.
Choosing which locking mechanism to use often boils down to:
- Whether contention is expected to be high or low
- Whether the lock is in or out of process context
- Whether sleeping is permissible
We tend to get these things for granted as we can conveniently just make use of those locking primitives and know that the race conditions that we are worried about won’t happen, but do you know how they work under the hood? No? Great! you are in the right place 😃
In this blog post I will cover how spinlock mechanism is implemented in the Linux kernel and walk you through the source code.
What are Spinlocks ?
Spinlock is probably the ‘simplest’ locking primitive that protects critical sections of code. This is conceptually how it works :
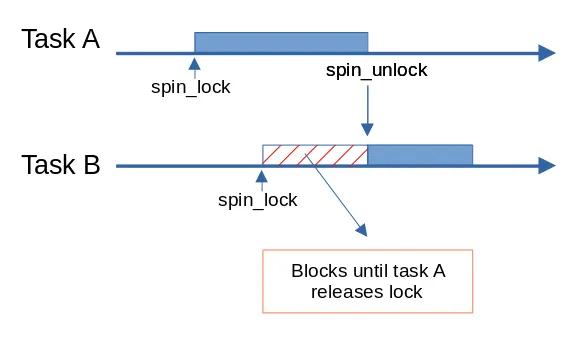
The key point to keep in mind is that if Task B can’t acquire the lock, it will wait in a loop (‘spin’) until the lock is released from Task A which automatically implies that Task B can’t go sleep. This behaviour dictates where it shouldn’t be used.
Spinlock exposes a set of convenient functions to kernel developers. Some of the most used functions are:
How do I use Spinlocks in my code ?
Using spinlocks in your code is pretty straightforward.
If one needs to disable interrupts on current processor for some reason:
Disclaimer: Kernel config used
What makes kernel code hard to read is the fact that code is added/removed depending on which configs are used. Having said that, this is the config I built my kernel with:
CONFIG_PREEMPT_RT = not set
CONFIG_LOCKDEP = not set
CONFIG_PREEMPT_COUNT=y
CONFIG_DEBUG_SPINLOCK = not set
CONFIG_MMIOWB = not set
CONFIG_PROFILE_ALL_BRANCHES = not set
CONFIG_PARAVIRT_SPINLOCKS = not set
CONFIG_SMP = y
Now that you understand the basics we can deep dive into each function to understand how they work. I will focus on spinlock_t struct, spin_lock_init() and spin_lock() functions as they are the most important ones.
spinlock_t struct
The spinlock definition and its members depend on which kernel configs are set. In our case, this is what the spinlock_t struct looks like:
When CONFIG_PREEMPT_RT isn’t set, the Kernel maps spinlock to raw_spinlock_t which essentially wraps the architecture-specific spinlock called arch_spinlock_t:
The architecture-dependent arch_spinlock_t in x86 is defined as follows:
PS.: Spend sometime getting yourself familiar with the struct members and their names, that will come in handy later on this blog post
You might have noticed that:
- I mentioned the x86 platform
- there is a #ifdef __LITTLE_ENDIAN in the struct
If that somehow caught your attention, you are not alone 😅. Then again, we all know that x86 endianness is little endian.
As it turns out, the arch_spinlock_t used in x86 architecture isn’t under linux/arch/x86/ but in a generic header file called include/asm-generic/qspinlock_types.h.
The rationale is very simple, unless things are widely different from one platform to another then it’s better to centralise code in a single place for readability purposes which explains why we have to deal with different endianness in there. However, that isn’t the case for the following platforms below:

spin_lock_init(lock)
This is the function the initialise a spinlock_t variable. Alternatively, one can use this handy macro that both declares and initialises a spinlock
This is what spin_lock_init() macro expands to:
Note how atomic_t ->val from arch_spinlock_t got initialised to 0 (remember that).
Also, if you are a seasoned C programmer then “do {} while (0)” is second nature to you but if you are still trying to come to grips with C then these links may help you:
To cut a long story short, “do {} while(0)” addresses a few well-known problems such as swallowing the semicolon, duplicate variable names and so on when dealing with macros that are comprised of compound statements.
spin_lock(lock)
This is the function that tries to acquire the lock. If it success on it first attempt then it simply returns, otherwise it takes the ‘slow-path’ and loops (“spin”) while trying to acquire the lock until it succeeds.
Disclaimer: There is a lot to unpack here and honestly speaking, each line in the previous code snippet deserves a dedicated blog post. Given that this one is about spinlocks, I will explain the main purpose of each line and leave links that you use to learn more about the subject.
preempt_disable
kernel preemption is a property possessed by the Linux kernel in which the CPU can be interrupted in the middle of executing kernel code and assigned other tasks (from which it later returns to finish its kernel tasks).
There are 3 preemption models that users can choose from when compiling the kernel as shown below.

preempt_disable() macro gets expanded to the following:
The takeaway on macro preempt_disable() is that it increments an internal structure that is read by the Linux scheduler so the scheduler knows that the current task can’t be preempted until preempt_enable() is invoked.
If you want to learn more about kernel preemption, LWN has a couple of old-yet-really-good articles about the subject:
spin_acquire(…);
This function is part of the Kernel’s lockdep system which is a fascinating idea. Lockdep system keeps track of locks as they are acquired and print warns messages when a potential dead-lock can happen in runtime.
I cannot overstate how helpful this system can be during development-phase of any kernel code as debugging race conditions can be absurdly difficult sometimes.
In our case, given that CONFIG_LOCKDEP isn’t set, that line translates into a no-op so I won’t dive any further on this. If you want to learn more about the subject this is where you should find good info:
- https://lwn.net/Kernel/Index/#Lockdep
- https://www.kernel.org/doc/Documentation/locking/lockdep-design.txt
LOCK_CONTENDED(…);
As mentioned before, due to the kernel configs used, this macro gets translated to do_raw_spin_lock(lock); which is essentially the place where the magic happens.
queued_spin_lock(…);
It’s in this function that we can see where spinlock get its name from. It tries to change the value of spinlock_t -> raw_spinlock_t -> arch_spinlock_t -> atomic_t (val) and if that succeeds then lock is effectively acquired. If not, then the slow-path will be taken so it can loop endlessly until it gets the chance to acquire the lock.
likely(x)
This is macro that gets expanded to __builtin_expect(!!(x), 1). Essentially, that gives indications for branch prediction optimisations to the GCC compiler so we can take advantage of the some of the CPU cache/proactive fetch features that some architectures have (Oversimplification of course).
If you want to learn more about that you may want to take a look at GCC’s docs:
atomic_try_cmpxchg_acquire(…);
It goes without saying that in order to deal with multiple concurrent tasks trying to compete for a coveted resource (a lock), one must ensure that the act of locking is done in a single instruction.
atomic_try_cmpxchg_acquire does exactly that and, as one could expect, this is architecture-dependent. In the case of x86–64 arch, if you follow the macro’s code maze, you will eventually find this piece of code:
x86 CMPXCHG assembly instruction will, in a single instruction, compare the atomic_t->val to 0, if that is true then _Q_LOCKED_VAL (which is 1) is set to atomic_t->val.
Another thing which is important to mention above the code above is the lock variable in line 12. The constant LOCK_PREFIX_HERE is passed down the chain of function invocations until it ends up referenced as the lock argument on line 12.
For uni-processor systems (UP), this will be a empty string but for Symmetric Multiprocessor systems (SMP), it will add the x86 LOCK instruction prefix to ensure operation is executed atomically among all CPUs as shown below:
Conclusion
Phew! That was quite a lot for a single blog post, am I right? 😅
To ensure that this blog post won’t get unnecessarily lengthy, I will finish part 1 here and create part 2 for the slow-path as this is quite a bit of code (around 250–300 lines).
I hope that you’ve enjoyed what you read and if I missed anything just let me know and I will fix it 😉
Happy coding everyone! 😃
Paulo Almeida
